Short Description
Azure SQL Database gives us the possibility to work with a database as a service. We don’t need to manage hardware, buy SQL license and things like that. The only thing that we need to focus on is the database content.
We will see later that there are features for backup, scaling and many more out of the box.
Main Features
Scaling
In this moment there are types of service tiers that can be used
Each tier had different performance levels that are starting from 5 DTU and can go up to 800 DTU. A DTU is Database Throughput Unit and is used to measure the performance of a database.
Database Size
You can start from small databases that have 2GB and you can go even to 500GB, with 1.6k threads in parallel and 19.2K open session.
High number of transactions
In this moment we can reach a maximum number of 735 transactions per seconds. Of course if you don’t need this performance you can go with the Basic tire where you can have around ~4-5 transactions per second.
Backup and export
We are allowed to create automatically backups of our database and store them in Azure Blobs. We can specify how often backups are created and the retention period.
Geo-Replication
Using this feature we can you can have in different regions a replica of your database that will be active (in read-only mode) in the case when the primary node status is shaky.
Active Geo-Replication – Similar with the one above, but the synchronization is made faster and you can have maximum 4 nodes in different regions. On top of this you can access secondary nodes in read-only mode.
Audit
You can active the audit functionality and have a trace off all actions that happen on your database, from access time to what was change, permissions and security expectations. This information can be analyzed and reports can be created automatically.
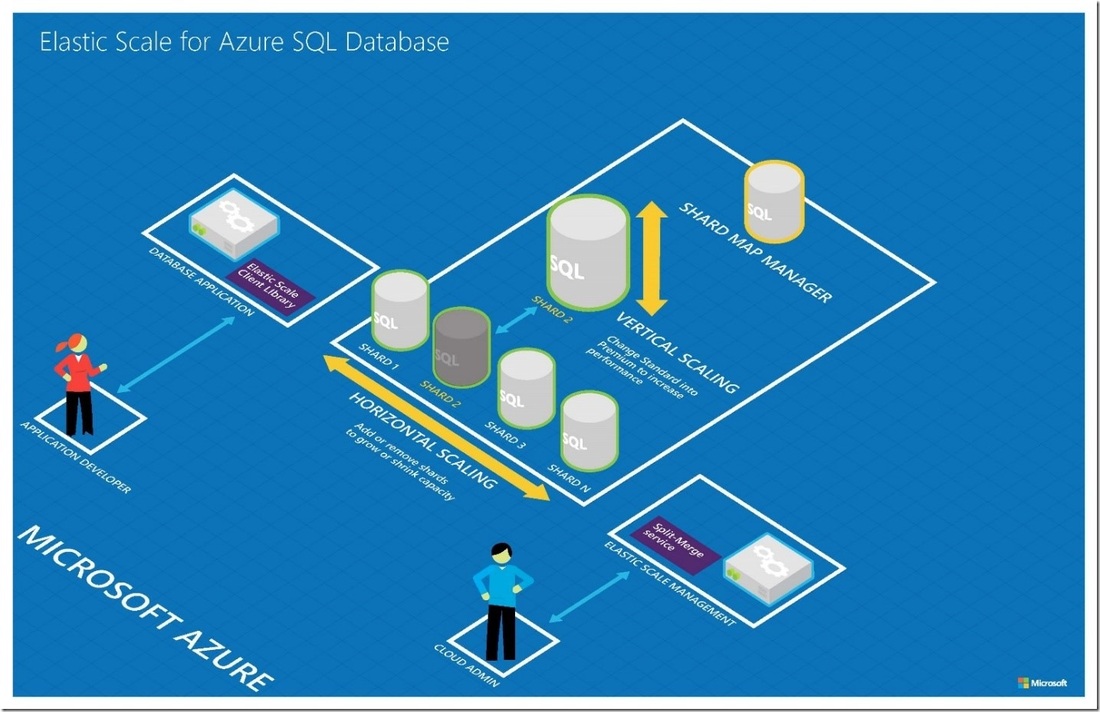
Elastic Scale
Database can scale automatically up or down based on application needs. Behind you create multiple shards automatically, based on your needs. You can control the number of shards that are created.
SLA 99.99%
Yes! This is great, especially because usually when database is down all your application is also down. So, YES, 99.99%.
No Maintenance and system down because of updates
Because we are talking about SQL as a service, there is no concept of system down because of maintenance or updates.
Limitations
There are some limitation because we use a SQL as a service. Because of this there are commands and actions that we cannot execute anymore.
RESTORE Command
This command is not supported, but we can restore database from portal of from power shell.
Attaching databases
Because we create a database we cannot attach one. As a work around we can create an empty database and restore a BACPAC.
SQL Jobs
In this moment there is no support for SQL Jobs, but future is blue.
Transaction Support
There is no support for distributed transactions
Cluster Index (Have to)
Each table has to have a cluster index. This is required before making the first insert to table.
User name restrictions
Some user names like: admin, administrator, guest, root, sa are restricted.
Connection idle time limit
The maximum idle connection time is 30 minutes.
Applicable Use Cases
Below you can find 4 use cases when SQL Azure is best option for us.
Shared Database
When we have a data base that need to be shared between multiple organizations. Using SQL Azure we can very easily manage, access and control the database.
Startups
When you have a startup is pretty hard to know how many users you will have, what the load will be. Using SQL Azure you can start from a small database and increase the power on it or decreased based on your needs. You will not need to spend money on licenses and hardware.
Peak Load
When you have an application that has from time to time peaks. You will pay only what you use and can scale automatically based on you needs (elastic scale). For the normal usage you can pay only what you need in that moment.
Geo-redundant
When you have data that needs to be available 99.99% of time and on top of this you cannot afford to lose data. Using SQL Azure you can have backups and replica in different location and you can switch to them when primary node is not stable anymore. The cost are less than implementing this by your own.
Code Sample
By default SQL Azure don’t allow connection from any IP. You need to change this configuration from SQL Azure Firewall. This can be made very easily. There are two levels of firewalls, one at SQL Database level that allow or restrict access based on IP and another one where user can define custom rules like IP range or what database has access each IP.
The connection to SQL Azure is made same like for a normal SQL Server. There is no need for samples.
Pros and Cons
Pros
Cons
Pricing
Pricing is based on what kind of tier you use (Basic, Standard, Premium)
If you use backups, don’t forget that you will pay the space used by backups on blobs
Outbound traffic between SQL Azure and clients that are not in the same datacenter (if is applicable)
Azure SQL Database gives us the possibility to work with a database as a service. We don’t need to manage hardware, buy SQL license and things like that. The only thing that we need to focus on is the database content.
We will see later that there are features for backup, scaling and many more out of the box.
Main Features
Scaling
In this moment there are types of service tiers that can be used
- Basic
- Standard
- Premium
Each tier had different performance levels that are starting from 5 DTU and can go up to 800 DTU. A DTU is Database Throughput Unit and is used to measure the performance of a database.
Database Size
You can start from small databases that have 2GB and you can go even to 500GB, with 1.6k threads in parallel and 19.2K open session.
High number of transactions
In this moment we can reach a maximum number of 735 transactions per seconds. Of course if you don’t need this performance you can go with the Basic tire where you can have around ~4-5 transactions per second.
Backup and export
We are allowed to create automatically backups of our database and store them in Azure Blobs. We can specify how often backups are created and the retention period.
Geo-Replication
Using this feature we can you can have in different regions a replica of your database that will be active (in read-only mode) in the case when the primary node status is shaky.
- There are four types of replication model available on Azure SQL:
- Point-in-time restore – Gives you the possibility to restore to a specific point in time (using backup features)
- Geo-Restore – Similar with the above one, but the back-up is created in different region (this will assure you that if something goes bad in that region, you backup can be still access)
- Standard geo-replication – You have a replica in a different region at in case something bad happens in the first region, the second one will be activated. In ‘idle’ you cannot access this database. Synchronization between this two tiers is made asyc.
Active Geo-Replication – Similar with the one above, but the synchronization is made faster and you can have maximum 4 nodes in different regions. On top of this you can access secondary nodes in read-only mode.
Audit
You can active the audit functionality and have a trace off all actions that happen on your database, from access time to what was change, permissions and security expectations. This information can be analyzed and reports can be created automatically.
Elastic Scale
Database can scale automatically up or down based on application needs. Behind you create multiple shards automatically, based on your needs. You can control the number of shards that are created.
SLA 99.99%
Yes! This is great, especially because usually when database is down all your application is also down. So, YES, 99.99%.
No Maintenance and system down because of updates
Because we are talking about SQL as a service, there is no concept of system down because of maintenance or updates.
Limitations
There are some limitation because we use a SQL as a service. Because of this there are commands and actions that we cannot execute anymore.
RESTORE Command
This command is not supported, but we can restore database from portal of from power shell.
Attaching databases
Because we create a database we cannot attach one. As a work around we can create an empty database and restore a BACPAC.
SQL Jobs
In this moment there is no support for SQL Jobs, but future is blue.
Transaction Support
There is no support for distributed transactions
Cluster Index (Have to)
Each table has to have a cluster index. This is required before making the first insert to table.
User name restrictions
Some user names like: admin, administrator, guest, root, sa are restricted.
Connection idle time limit
The maximum idle connection time is 30 minutes.
Applicable Use Cases
Below you can find 4 use cases when SQL Azure is best option for us.
Shared Database
When we have a data base that need to be shared between multiple organizations. Using SQL Azure we can very easily manage, access and control the database.
Startups
When you have a startup is pretty hard to know how many users you will have, what the load will be. Using SQL Azure you can start from a small database and increase the power on it or decreased based on your needs. You will not need to spend money on licenses and hardware.
Peak Load
When you have an application that has from time to time peaks. You will pay only what you use and can scale automatically based on you needs (elastic scale). For the normal usage you can pay only what you need in that moment.
Geo-redundant
When you have data that needs to be available 99.99% of time and on top of this you cannot afford to lose data. Using SQL Azure you can have backups and replica in different location and you can switch to them when primary node is not stable anymore. The cost are less than implementing this by your own.
Code Sample
By default SQL Azure don’t allow connection from any IP. You need to change this configuration from SQL Azure Firewall. This can be made very easily. There are two levels of firewalls, one at SQL Database level that allow or restrict access based on IP and another one where user can define custom rules like IP range or what database has access each IP.
The connection to SQL Azure is made same like for a normal SQL Server. There is no need for samples.
Pros and Cons
Pros
- Stable
- SDK is comprehensive and well documented
- Very fast and fits into development workflow
- Easy to scale
- Ready for enterprise
- Easy to port existing code
- Backup support
- Geo-Replication
Cons
- No distributed cache
- Some SQL features are not available
- No support for large database (2TB for example, but future is BLUE or we can split them)
Pricing
Pricing is based on what kind of tier you use (Basic, Standard, Premium)
If you use backups, don’t forget that you will pay the space used by backups on blobs
Outbound traffic between SQL Azure and clients that are not in the same datacenter (if is applicable)