Prerequisites
Setup
- Create an Azure Machine Learning Experimentation account.
- Azure Machine Learning Workbench installed
Setup
- Start of by cloning the repository on your local machine.
- The files needed for the experiment are located under 1-AML-Titanic
- Open Azure Machine Learning Workbench and add the project to your work space
If it is not possible to add the folder, please copy just the Titanic example to a different folder
Get your Data in place
Preparing the data is one of the key steps for your first ML experiment. This step includes renaming of columns, filtering (e.g. removing null val]ues), transforming values and changing the data type.
- Fill in the Project name and Project directory boxes. Project description is optional but helpful. Leave the Visualstudio.com GIT Repository URL box blank for now and choose a workspace (created in the installation guide).
Get your Data in place
Preparing the data is one of the key steps for your first ML experiment. This step includes renaming of columns, filtering (e.g. removing null val]ues), transforming values and changing the data type.
- To begin the process, add your dataset titanic.csv as a new Data Source to the experiment and follow the steps.
(Please note: The project you cloned already has a fully prepared dataset included. However, to get a glimpse of how things work we recommend to try it out on your own.)
Data Exploration
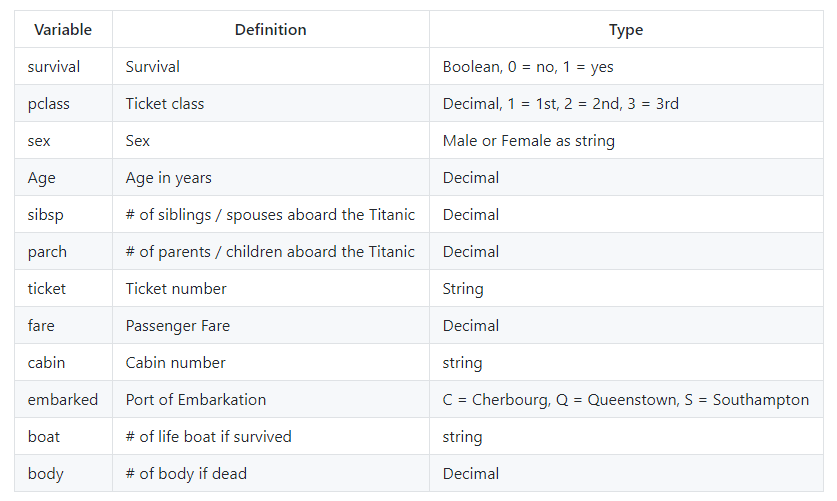
In the titanic.csv file you can find the data imported and used in the model creation. Before we get started with preparing the data for the experiment, let's have a quick look at what the data is about.
Data Exploration
In the titanic.csv file you can find the data imported and used in the model creation. Before we get started with preparing the data for the experiment, let's have a quick look at what the data is about.
To get to know your data even better by exploring certain statistical figures click on Metrics in the top bar of the data section:
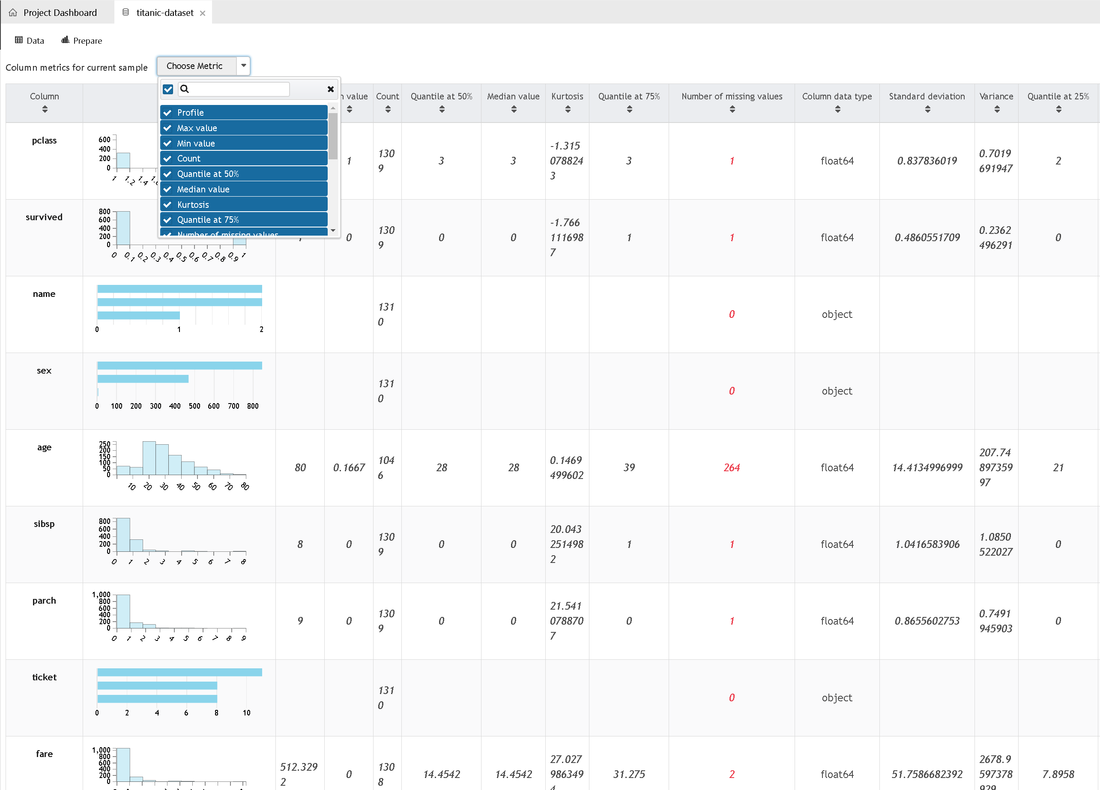
Data Preparation
Now it's time to get our hands dirty and prepare our data. The following steps are about getting rid of data we don't need, removing incomplete data and transforming data types, but let's take one step after the other:
Now it's time to get our hands dirty and prepare our data. The following steps are about getting rid of data we don't need, removing incomplete data and transforming data types, but let's take one step after the other:
- To start off, create a new Preparation file
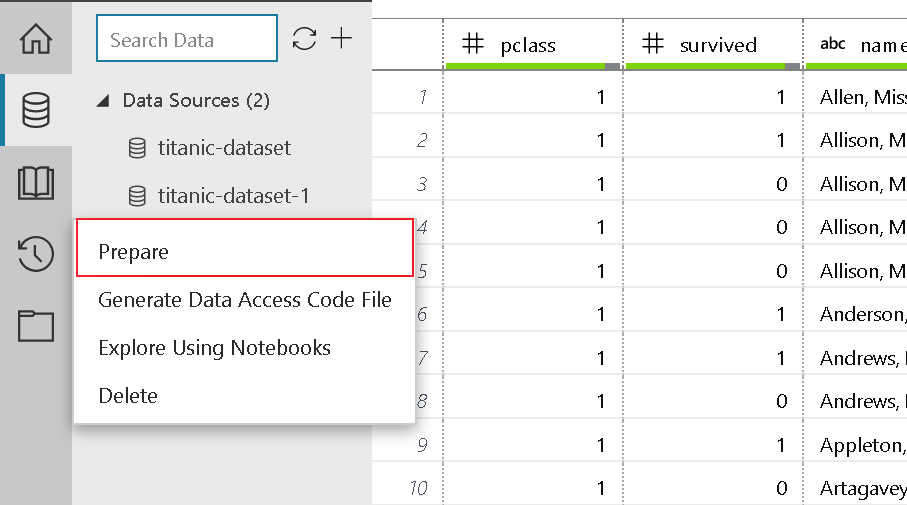
- Select the Prepare button. The Prepare dialog box opens.
- The sample project comes with an titanic-clear.dprep file. By default, it asks you to create a new data flow in the titanic-clear.dprep data preparation package that already exists.
- Select + New Data Preparation Package from the drop-down menu, enter a new value for the package name, use titanic-clear-1, and then select OK.
- Let's start with removing the columns we don't need. Therefore select the column "name" and click "remove". (right-click on the column head)
- Repeat this for the columns ticket, embarked, cabin, boat, body and home.dest
- Next we filter the pclass for empty values
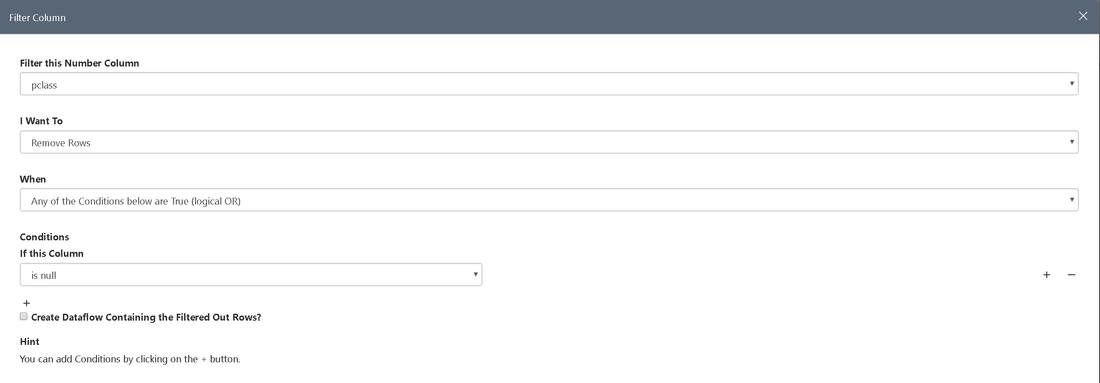
Repeat this for the columns fare and age
- We also want sex to be a numeric value (female = 1, male = 0). To do so, we have to select "Replace Values". This is necessary due to limitations the Machine Learning algorithms dictate
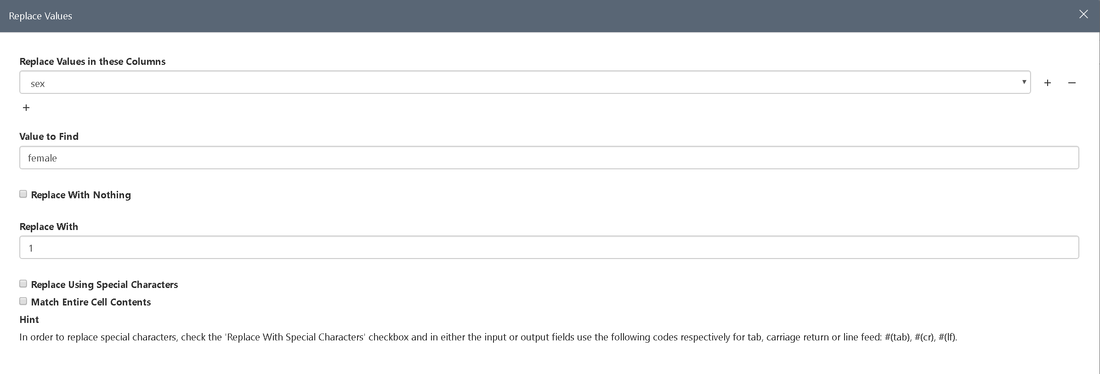
Repeat this for male.
To make sex a numeric value we only have to click on the column header and select the numeric option.
To make sex a numeric value we only have to click on the column header and select the numeric option.
- Last but not least, we want to change the precision of the columns age and fare
- Info
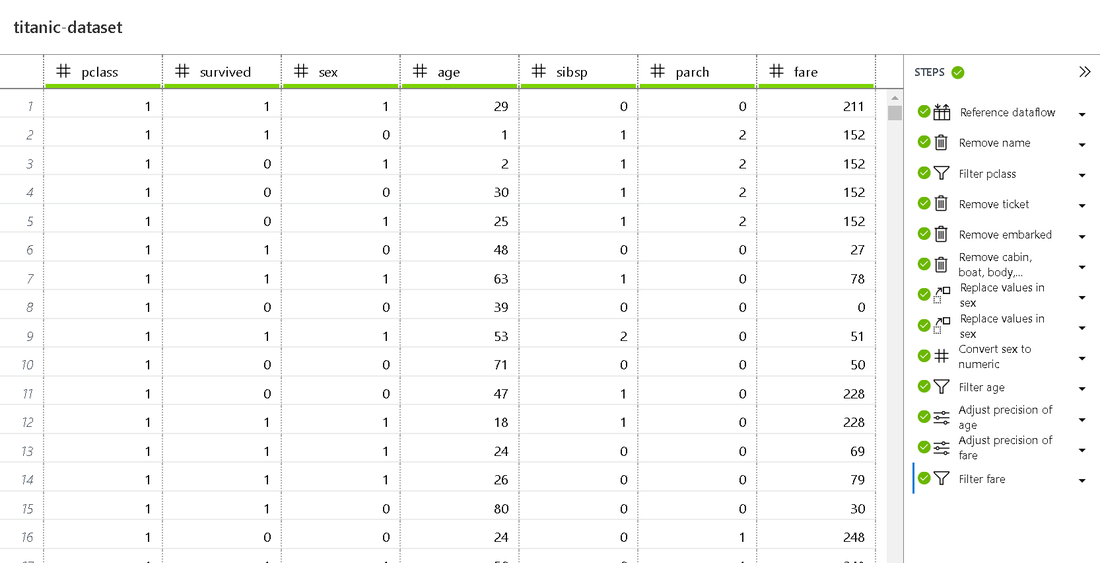
Here you can view, change and edit single steps performed during the preparation process.
The result of the above-mentioned steps should be the same as the dataset prepared in the demo.
For more information on how to prepare data in Azure Machine Learning Workbench, see the Get started with data preparation guide.
Develop the Model
At this stage we have our data sources configured and prepared for the fun part you've probably been waiting for - developing the ML model. To make things a little bit easier, we already added the train.py file to the project. Open the file and try to make yourself familiar with the code. Basically the script performs the following steps:
The result of the above-mentioned steps should be the same as the dataset prepared in the demo.
For more information on how to prepare data in Azure Machine Learning Workbench, see the Get started with data preparation guide.
Develop the Model
At this stage we have our data sources configured and prepared for the fun part you've probably been waiting for - developing the ML model. To make things a little bit easier, we already added the train.py file to the project. Open the file and try to make yourself familiar with the code. Basically the script performs the following steps:
- Loads the data preparation package titanic-clear.dprep to create a pandas DataFrame.
- Splits the dataset into a training and a testing set ( 65% / 35% )
- Uses the scikit-learn machine learning library to build a logistic regression model.
- Serializes the model by inserting the pickle library into a file in the outputs folder.
- The run_logger object is used throughout to record the model accuracy into the logs. The logs are automatically plotted in the run history.
The deserialized model, saved in the ouputs folder, can later be used to make a prediction on a new record but first things first.
Run your Python Script
We are now ready to run the script on your local computer.
Run your Python Script
We are now ready to run the script on your local computer.
- Select local as the execution target from the command bar near the top of the application, and select train.py as the script to run. There are other files included in the sample that we will check out later.

- Click the Run button to begin running train.py on your computer.
- The Jobs panel slides out from the right if it is not already visible, and an train job is added in the panel. Its status transitions from Submitting to Running as the job begins to run, and then to Completed in a few seconds.
- Congratulations. You have successfully executed a Python script in Azure Machine Learning Workbench.
After running the script 2-3 times feel free to check the results in the Jobs History.
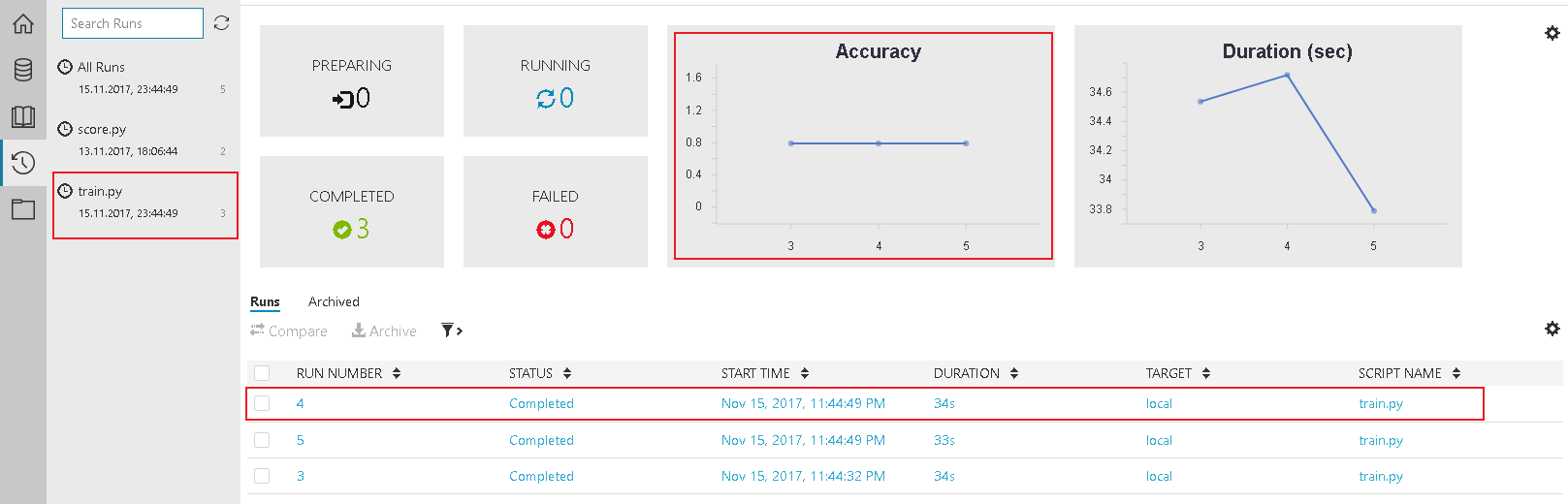
Accuracy shows you how accurate your script works. The list of Jobs below show a historical list of the scrips you ran. By selecting one job you get a detailed overview.
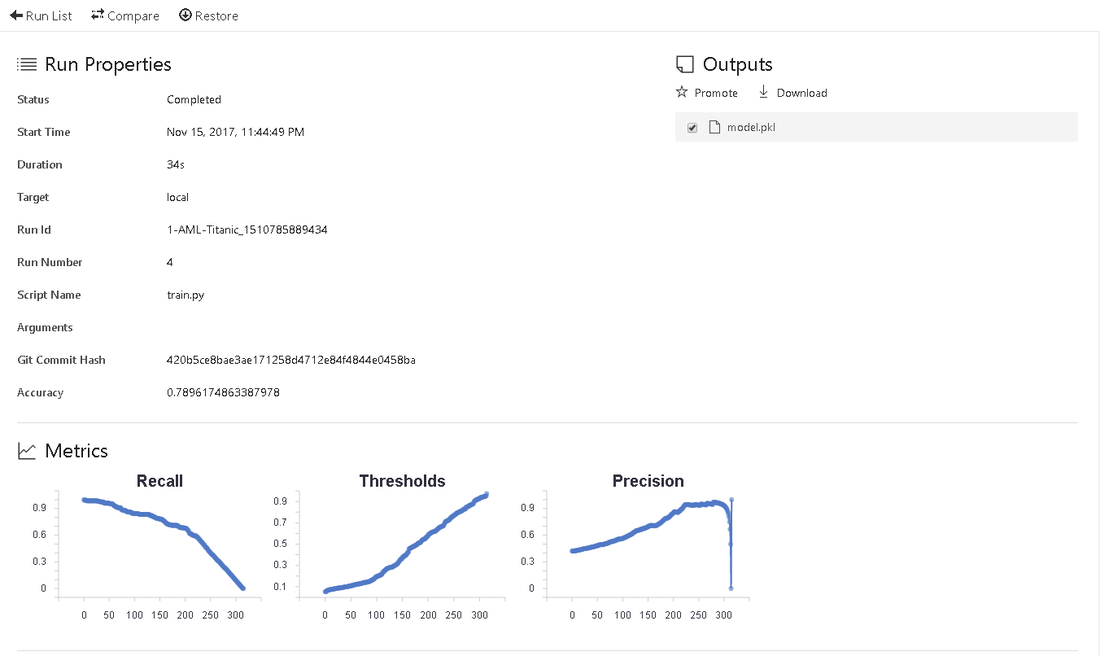
Deploy your Model
Before we can think about deploying our experiment we have to figure out, if our model actually works. Therefor, it is important to download and save the model, created by our train.py script. The model.pkl file is saved in the output section of the log.
Before we can think about deploying our experiment we have to figure out, if our model actually works. Therefor, it is important to download and save the model, created by our train.py script. The model.pkl file is saved in the output section of the log.
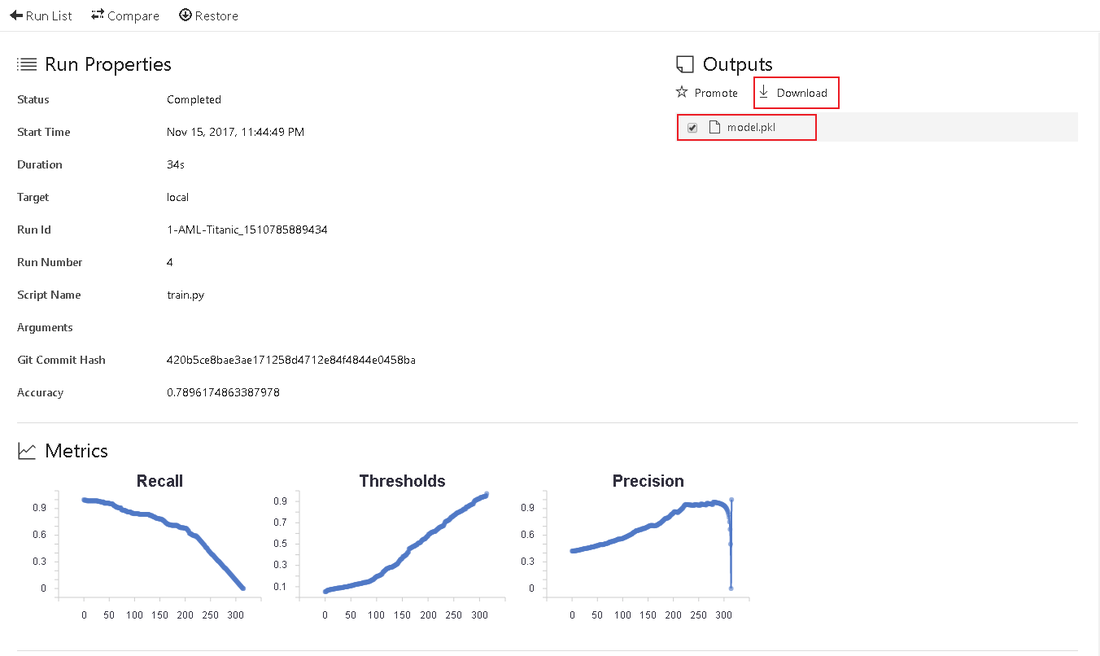
This file is used in our second script - score.py. This file loads the model.pkl and tests it against predefined test data. The result is a JSON-Object. You can find it in the Jobs history under the score.py section. Selecting a certain Job in the list will take you to a detailed overview.
To publish the model, we have to perform these actions:
To publish the model, we have to perform these actions:
- Run the score.py file, which creates a json file, that contains the schema for your input
- save the service_schema.json in the root of your project (same location as train.py)
- open your command prompt in the AML Workbench (To left option: File -> Open Command Prompt )
- Take a look at the Prepare to operationalize locally section of the official documentation
- After the preparation, you can create the real-time web service in one command:
- after deployment, the service will provide you with options to call you service
[Optional] Deploy the model in the cloudTo upload the docker file to Azure, we just have to create a Web Service for Containers in Azure. As the last command (deploy web service in one command) created a Docker image and also an Azure Container Registry, this is fairly easy to do:
- Log in to the Azure portal and search for "Web App for Containers"
- Create the Web App and configure your container. This is quite staightforward, as you just have to choose the one, that is already created for you.
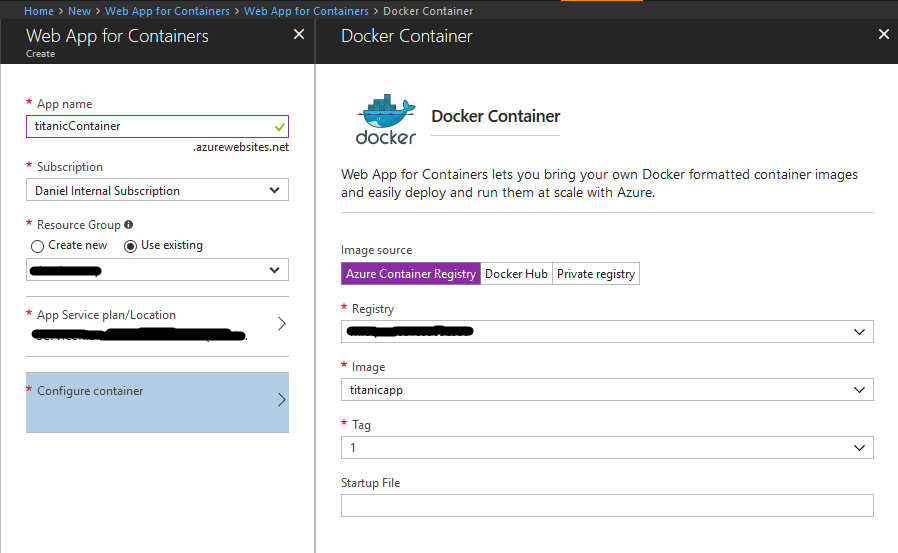
- Save the settings and create the service
- After setting up the service, wait some time (depending on model size) until it is ready. Now you can call it via HTTP. You can use this Jupyter notebook to guide you through the call.
- [Optional]: Set the Always On option in the Application Settings of your App Service to "On". This way, the it is always ready and will not shut down, when unused.
Summary
What we did:
What we did:
- Setup Azure Machine Learning Workbench
- Created a project
- Added a new Data Source
- Prepared the data in order to be able to process it
- Ran your first training scripts and created a model
- Used the model to test your data and classify it
- Deployed your model on our machine (and as a web service)

