Azure Data Factory is one of the services that is part of data analytics functionality offered by Microsoft Azure. This service can be used with success when you need to orchestrate and manage data movement and different data transformation.
Main Features
Move data between different sources
Using Azure Data Factory you can move data between different storages, from the file based one, to SQL and even NoSQL storages. This can be very useful when you need to change the location of data to be able to process or store it for long time.
On-premises and Cloud
The data storage used as input or output can be not only on Microsoft Azure but also in another storages that can be on-premises.
Data Source Aggregation
We have the ability to combine multiple data sources in only one data sources. In this way we can easily merge different data sources.
Data Processing
All the input data sources can be processed and base transformation functions can be applied on them. In this way we can monitor our data.
Complex data transformation
Data Factory supports complex transformations functions, being able to use external components like Pig, Hive, HDInsight or C# libraries.
Configurable
There is full support for custom behaviors and fault-tolerance. We have the ability to manage clusters, change the retry policy, the alert rules and timeouts policy.
Management
The management of pipelines can be made using different tools from PowerShell scripts to .NET libraries.
Workflow
Data processing and pipeline management can be managed easily using a simple workflow UI. Using this workflow the pipeline configuration is very simple.
Linked Services
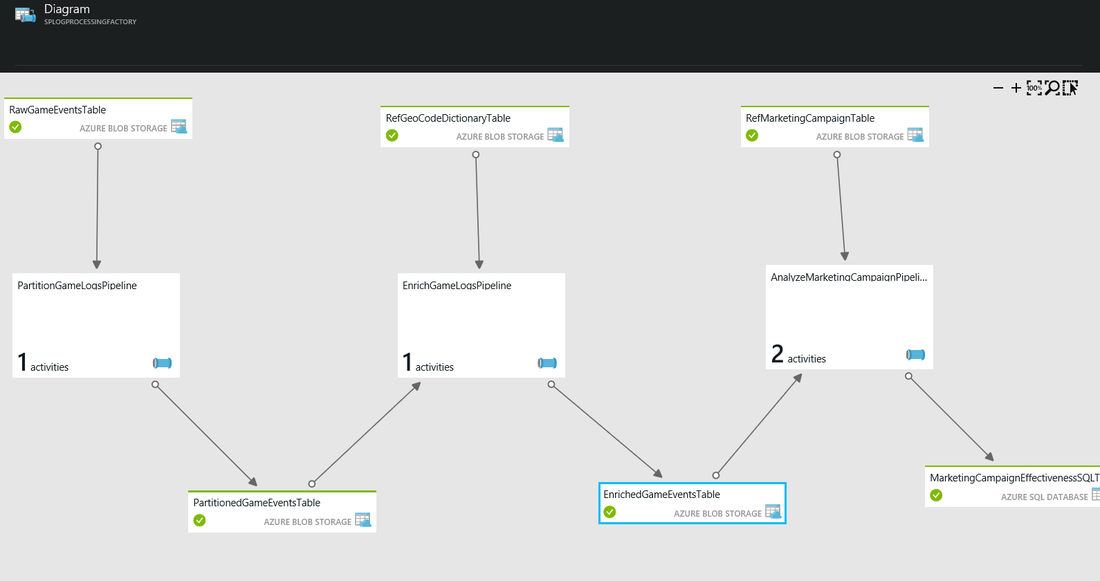
A linked service is represented by an external data source like a blob storage or a SQL database. A linked resources can be also a computing service. We can link one or more linked services.
Input/Output Tables
It is a rectangular dataset that is used for data that are coming to Data Factory or that are produced by it. This tables are produces from the linked resources data stored and can be persistent in external data sources. The JSON format is used for this tables.
Pipeline
A pipeline is an action that is executed over inputs table and produce some data in the output table(s). Over the this data we can apply different processing and transformation operations.
Limitations
One of the current limitations is the on-premises storages type that is supported in this moment. Now, only SQL Server is supported for on-premises sources.
Applicable Use Cases
Below you can find some use cases when I would use Azure Data Factory.
Logs file processing
Logs can be produced by multiple data sources and can be stored in different data sources. We can use Azure Data Factory to fetch data from all data sources and combine all this logs in only one location, having the same format of data.
Transform data to the same format
If we work with different legacy system we will have data in different formats. Data Factory can be used with success to aggregate all this data and transform to a common format.
Code Sample
A great sample can be found on the fallowing address: http://azure.microsoft.com/en-us/documentation/articles/data-factory-troubleshoot/
Pros and Cons
Pros
Integration with on-premises data sources
Support multiple data sources
Aggregation and transformation of data can be made easily
Cons
In this moment there is no support for other on-premises data sources except SQL Server.
Pricing
If you want to calculate the cost of Azure Data Factory you should take into account:
Move data between different sources
Using Azure Data Factory you can move data between different storages, from the file based one, to SQL and even NoSQL storages. This can be very useful when you need to change the location of data to be able to process or store it for long time.
On-premises and Cloud
The data storage used as input or output can be not only on Microsoft Azure but also in another storages that can be on-premises.
Data Source Aggregation
We have the ability to combine multiple data sources in only one data sources. In this way we can easily merge different data sources.
Data Processing
All the input data sources can be processed and base transformation functions can be applied on them. In this way we can monitor our data.
Complex data transformation
Data Factory supports complex transformations functions, being able to use external components like Pig, Hive, HDInsight or C# libraries.
Configurable
There is full support for custom behaviors and fault-tolerance. We have the ability to manage clusters, change the retry policy, the alert rules and timeouts policy.
Management
The management of pipelines can be made using different tools from PowerShell scripts to .NET libraries.
Workflow
Data processing and pipeline management can be managed easily using a simple workflow UI. Using this workflow the pipeline configuration is very simple.
Linked Services
A linked service is represented by an external data source like a blob storage or a SQL database. A linked resources can be also a computing service. We can link one or more linked services.
Input/Output Tables
It is a rectangular dataset that is used for data that are coming to Data Factory or that are produced by it. This tables are produces from the linked resources data stored and can be persistent in external data sources. The JSON format is used for this tables.
Pipeline
A pipeline is an action that is executed over inputs table and produce some data in the output table(s). Over the this data we can apply different processing and transformation operations.
Limitations
One of the current limitations is the on-premises storages type that is supported in this moment. Now, only SQL Server is supported for on-premises sources.
Applicable Use Cases
Below you can find some use cases when I would use Azure Data Factory.
Logs file processing
Logs can be produced by multiple data sources and can be stored in different data sources. We can use Azure Data Factory to fetch data from all data sources and combine all this logs in only one location, having the same format of data.
Transform data to the same format
If we work with different legacy system we will have data in different formats. Data Factory can be used with success to aggregate all this data and transform to a common format.
Code Sample
A great sample can be found on the fallowing address: http://azure.microsoft.com/en-us/documentation/articles/data-factory-troubleshoot/
Pros and Cons
Pros
Integration with on-premises data sources
Support multiple data sources
Aggregation and transformation of data can be made easily
Cons
In this moment there is no support for other on-premises data sources except SQL Server.
Pricing
If you want to calculate the cost of Azure Data Factory you should take into account:
- Number of activities
- Outbound traffic (from on-premises data sources)
- Run on Azure data sources or on-premises

